本文仅适用于互联网web开发者。
我们在看到一个网站的时,首先关注到的多是它的界面设计,美观并炫酷的页面,是让我们对它的开发者产生敬意的最容易的方式。
抛开界面和用户交互之后,从代码实现上,怎么才能看出一个网站的技术优雅而精致呢?
互联网从业者,不管是前端还是后端,肯定对这个问题多多少少都考虑过,但是我们的方向大概只有两个:一个是从用户角度提高访问速度,一个是从开发者角度提高可维护性。
至于网站的性能优化,相信大家也可以侃侃而谈,前端会大谈特谈 Vue 和 React,他们的周边生态,后端会聊起 Java 和 PHP,甚至 GoLang,告诉你缓存和分布式。
我最近关注到一个美国的珠宝电商网站 Brilliant Earth,它还用到了国内开发者嗤之以鼻的 jQuery,因为最近我想爬取一些他们的商品图和信息,这个过程中我发现了几处细节,让我对这个网站的开发者十分钦佩,钦佩到要专门写一篇文章来讲一讲。
接口设计
前些年我们特别喜欢谈前后端分离,现在现在我们多数开发团队都实现了它,导致公司招聘前后端至少2个人才能组队。工作中前后端的界限也十分明显,两者通过接口URL来对接。
基于我们前文提到的两个方向,访问速度和可维护性,前后端分离这种方式对开发者确实十分“友好”,也能在用户访问体验上做些文章,但是对搜索引擎十分不友好,于是硬生生又创造出“SSR”(服务器端渲染)这样的名词。
后端在提供给前端接口的时候,多数采用了 JSON 格式,供前端方便地组织、渲染数据。但是这样的接口也很容易被“恶意”地爬取,尤其是一些行业数据类的网站,比如京东的商品信息、豆瓣的电影图书等等。尤其是豆瓣,自己的后端接口开发出来多是被其他应用调用,浪费了大量服务器资源。
其实网站既然能被访问,就难逃被爬的命运。反爬的策略也只是提高一下爬取的门槛儿。常见的方式多是携带特殊参数、验证请求headers、cookies等等。
比如豆瓣,后端接口要求携带 apiKey,并验证了 header 中的 Referer 和 User-Agent,但是这种策略很容易被绕过,参见《豆瓣开发者不完全指南》。
Brilliant Earth 非常适度地使用了前后端分离,并且借用了浏览器的 replaceState 属性来避免爬取,这是我第一次见到这种反爬策略。
进一步解释一下,我们在豆瓣电影首页找到某个XHR请求,复制为 cURL,然后到命令行/终端界面直接输入后回车,就可以看到返回的前端所需数据。
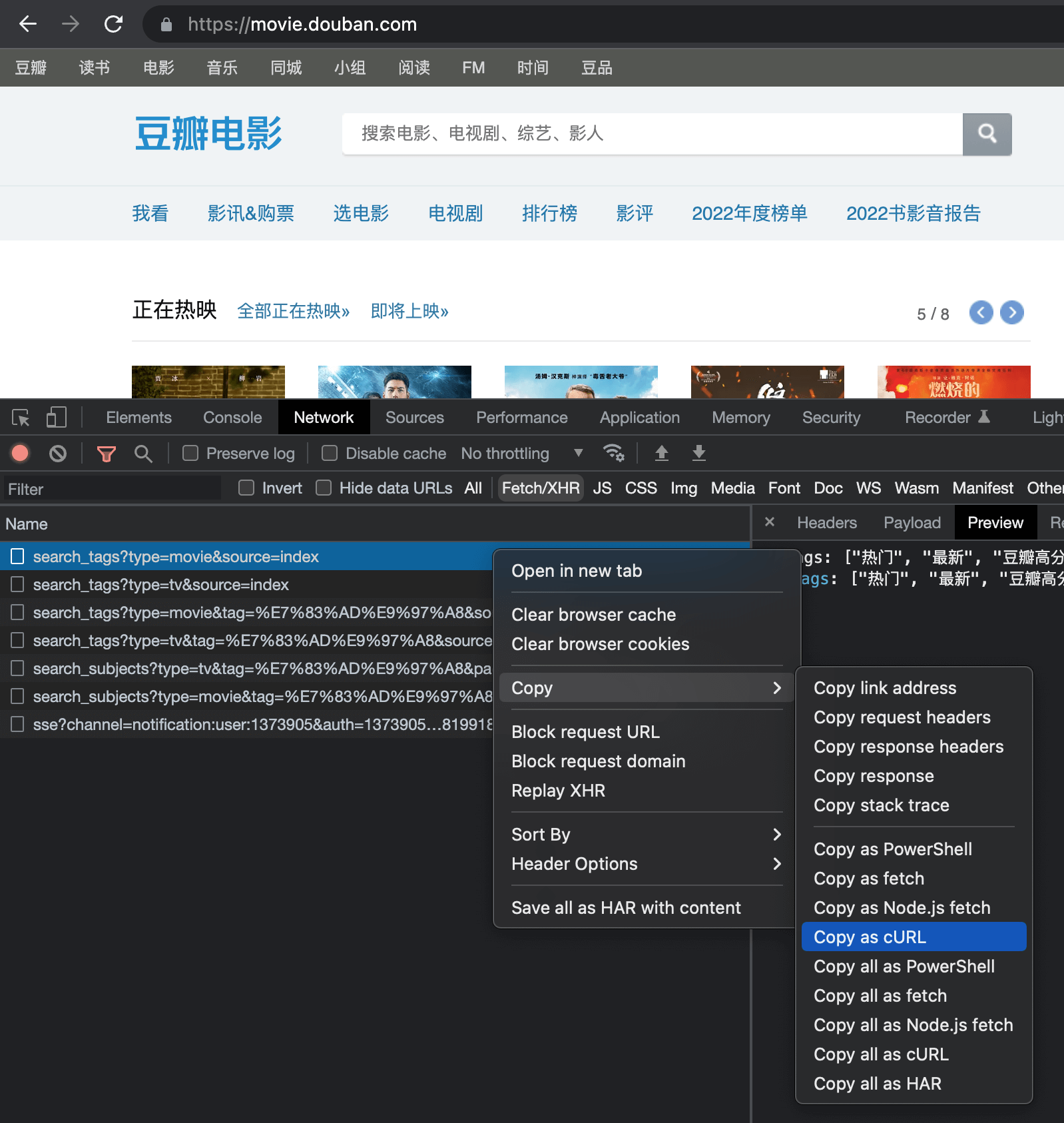
根据请求中的信息(如参数、headers、cookie等),我们便可以在 Postman 类工具中模拟浏览器请求接口数据。
但是我们使用同样的方法操作 Brilliant Earth 的接口,会发现返回的数据并不是预期的。你可以在如下图所示的 sapphire 产品列表页试一下相关接口:
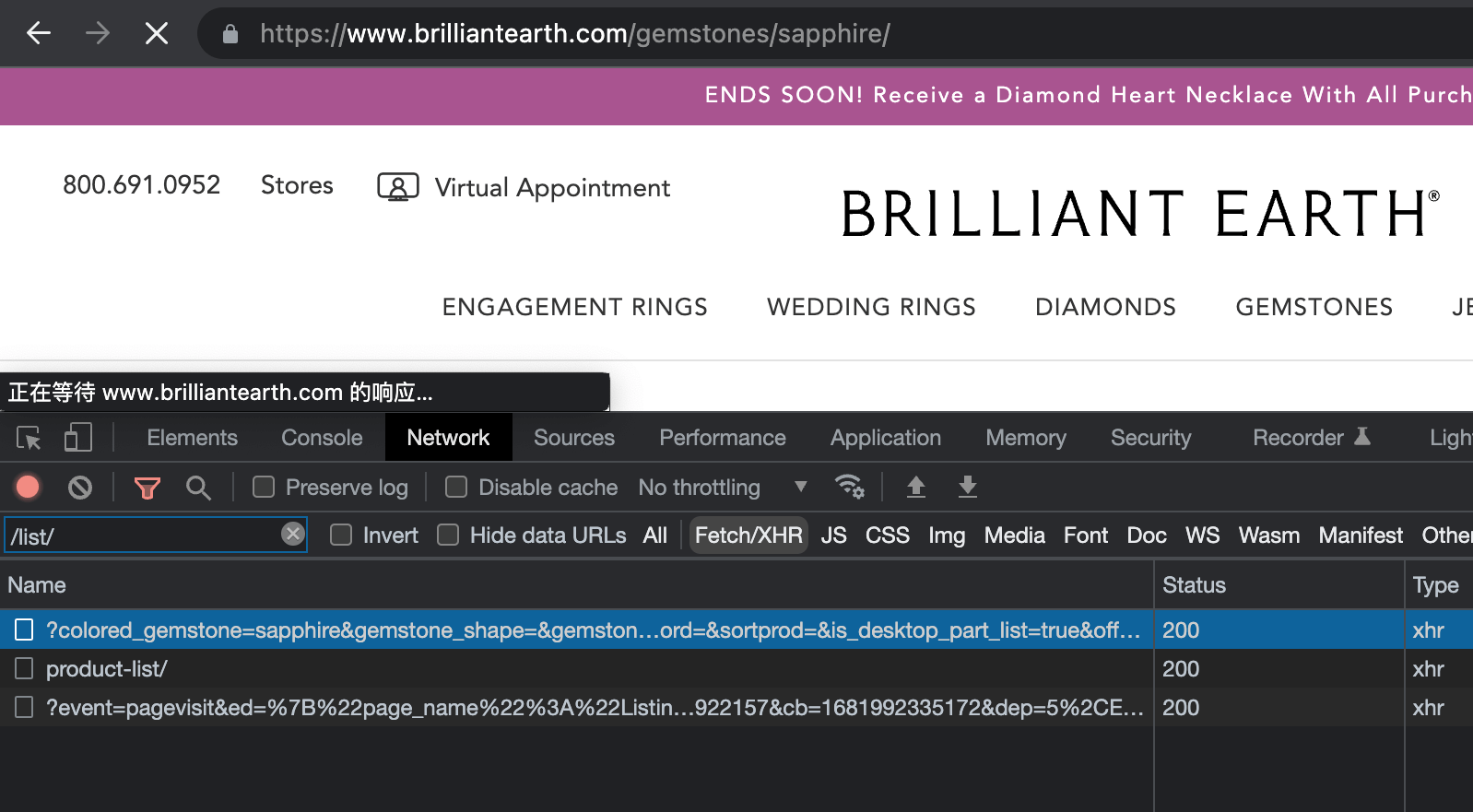
你发现返回的并不是产品列表的数据,而是一个带有 history.replaceState 代码的页面,这个页面上是服务器端生成的一些二次验证的参数,需要再次提交才能拿到真正所需的数据。
如果在浏览器里面,接口会通过 replaceState 自动跳转到下一步,而如果你如果使用命令行/代码/Postman 爬取,就无法直接拿到结果。
当然,我前面也有说,任何反爬策略都可以被绕过,但是 Brilliant Earth 是我见过最“聪明”的反爬策略了。
图片加载
在 Brilliant Earth 的产品详情页,提供了产品的360°视图,通过鼠标拖拽可以通过各个角度查看产品。
比如下面这个海蓝宝戒指,红框中左侧的戒指和右侧裸石都是可以360°查看的。左侧戒指采用的是一个叫 ImgJize 的第三方服务,右侧裸石采用的是 VISION 360°,是一个专门拍摄宝石并提供展示服务的印度公司。
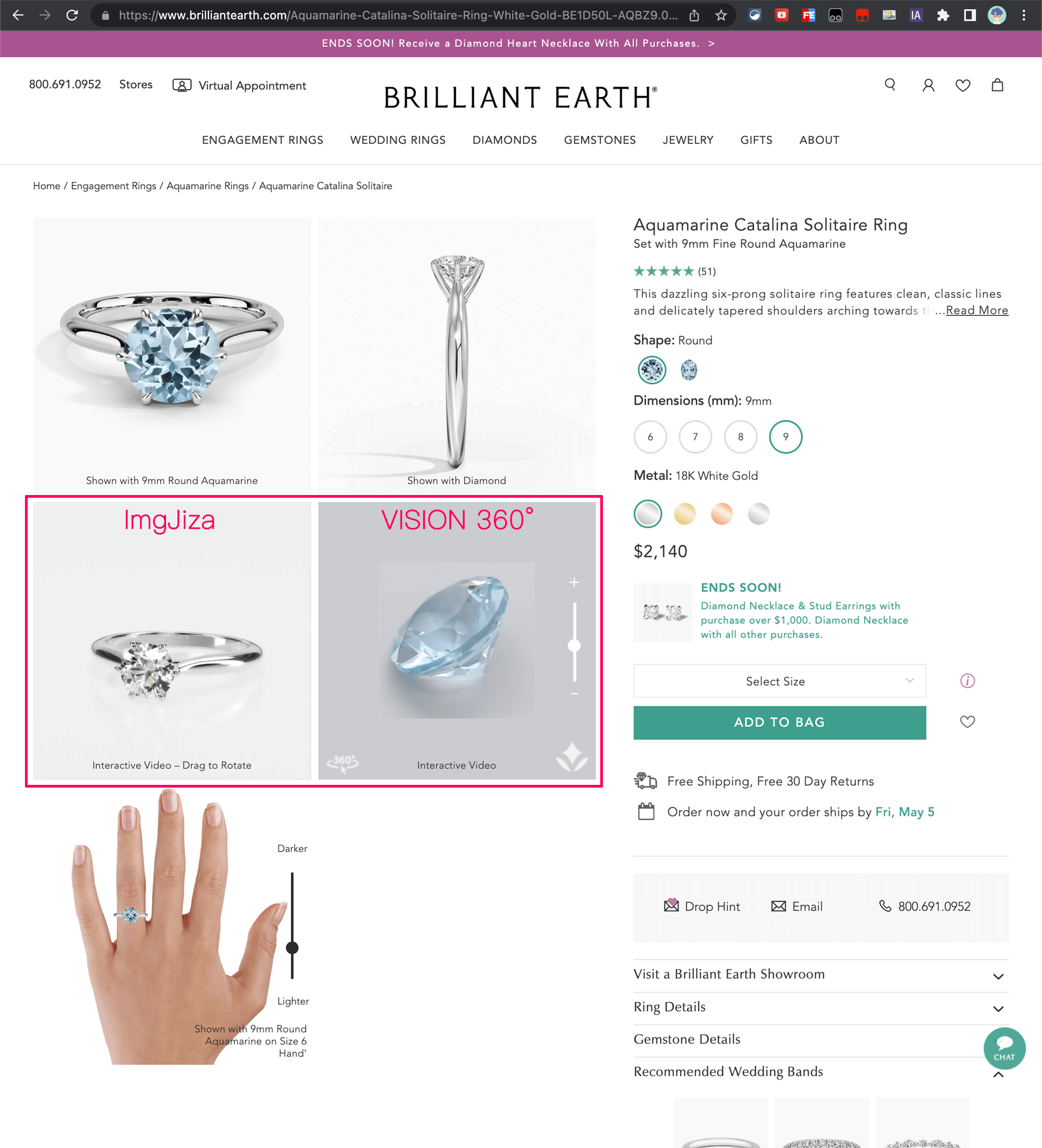
因为这两个视图都是通过 iframe 引入到 Brilliant Earth 页面的,所以他们的加载和相关技术和 Brilliant Earth 的页面互不影响,我们拆开来看看。
左侧展示戒指的 ImgJize 用的是大多数开发者的方法,他们环绕着戒指拍了 192 张照片,然后通过 <img /> 标签引入图片,循环显示便完成了一个360°视角的动画。
VISION 360° 在右侧的裸石视图上就更为巧妙。他们使用了 256 张图片,但是这些图片是分量加载的。
他们先从 256 张图片张图片中按等分角度(90°)挑选 4 张,组成圆周 4 个角度的视图,将这 4 张图片转成 base64 格式的数据放到一个 json 文件里面,命名为 1.json。
使用 base64 可以保证这 4 张图同时加载,而避免了随着图片增加,不同的图片加载时间不一致的问题。比如 ImgJize 的方式,要等 192 张图片全部加载完成才能开始展示。而 VISION 360° 只要加载了最初的 4 张图,就可以开始展示一个 360° 动画,虽然这个动画连贯性目前还很差。
下一步,开发者从上一步 4 张图的每两个图的角度中间的角度各选一张图,得到 4 张图放到 2.json 里面,等 2.json 加载完,便得到了 8 张图片,增加了动画的连贯性。然后再从 8 张图的每两图之间继续抽出一张图,一共 8 张图放到 3.json,得到 16 张图……再取 16 张、32张、64张、128张,一共 7 个 JSON 文件,得到 256 张图。
这 256 张图渐进式地加载完,便完成了一个非常顺滑的圆周视图动画。
不过这里他们还有一个非常有趣的处理,通过 JSON 得到的这 256 张图,并不是按照圆周角度的顺序排放的。也就是说,你就算爬取到了这 256 张图,如果想连贯的按照 360° 播放,还需要一张一张图查看,手动地去排好序才能使用。
VISION 360° 自己使用这些图片的时候,额外提供了一个记录图片顺序的数据,而这个数据是经过加密的。这样就大大提高了爬取者的成本,就算你拿到了他们网站所有的图片,也没法做一个 360° 的展示功能,需要人工对每个产品、每个图识别、排序之后才能使用。
遗憾的是,检查网站的 js 文件,虽然代码经过了混淆加密处理,但是 CryptoJS 这个字眼过于明显,通过细心地查找,不难发现解码的 key。
还是那句话,反爬策略只能增加了爬取者门槛和成本,总能有办法破解。
您的赞助将会支持作者创作及本站运维

评论
共2条聪明
好
发表评论